Reduce Kafka traffic costs by up to 25% with one simple configuration change. Running a real-time data streaming platform at scale is expensive, but it doesn’t have to break your budget.
At Grab, our Kafka infrastructure serves millions of events daily across Southeast Asia’s leading superapp. However, there was one line item on our AWS bill that kept growing: cross-availability zone (cross-AZ) traffic charges.
Does this sound familiar? If you’re running Kafka on AWS, you’re probably bleeding money on network transfer costs too. Fortunately, we discovered a game-changing solution that can reduce Kafka traffic costs dramatically.
The $100K Problem Hidden in Plain Sight
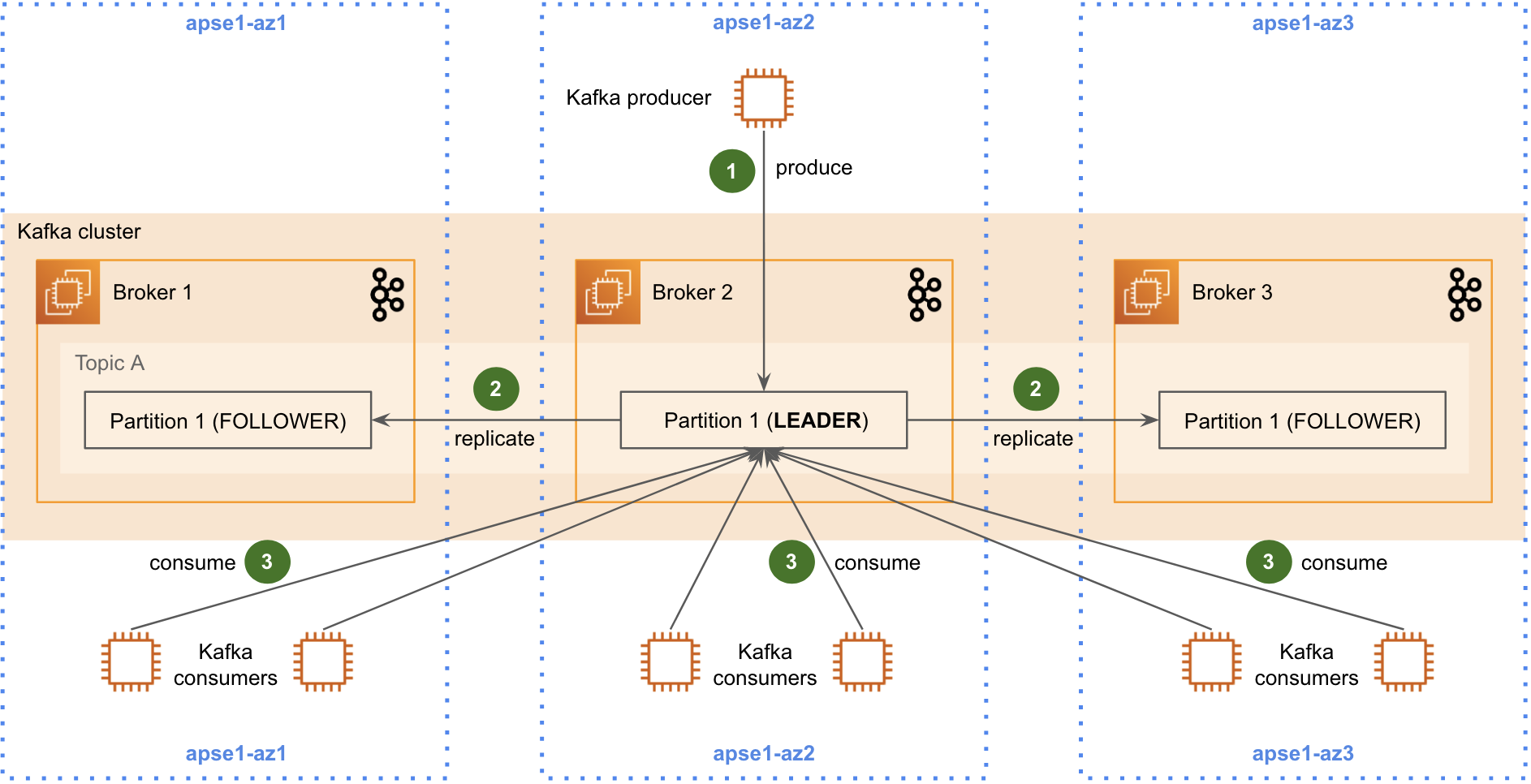
Picture this scenario: You’ve got Kafka brokers spread across three availability zones for high availability. Smart move, right? Additionally, your partition replicas are distributed perfectly for resilience.
However, here’s what’s quietly draining your budget:
By default, every Kafka consumer talks only to partition leaders.
With three AZs, there’s a 67% chance that leader lives in a different zone from your consumer. Every. Single. Time.
Furthermore, the math is brutal:
- Producer → Leader (minimal cross-AZ cost)
- Leader → Followers (2x replication cost)
- Consumers → Leader (massive cost multiplier)
That last bullet point? It was eating 50% of our total Kafka platform costs. Consequently, we knew we had to find a better solution.
The Game-Changing Solution (It’s Simpler Than You Think)
Kafka 2.3 introduced a feature that most teams overlook: replica fetching for consumers.
Instead of always hitting the partition leader, consumers can now read from the replica in their own AZ. As a result, you get zero cross-AZ traffic and zero extra charges.
Moreover, here’s the beautiful part: the data is identical across all replicas. Therefore, you’re not sacrificing consistency for cost savings.
Our Step-by-Step Implementation Guide
Phase 1: The Kafka Upgrade Journey
Initially, we jumped straight to Kafka 3.1 (skipping 2.3) for better stability and bug fixes. Here’s our zero-downtime upgrade strategy:
1: Zookeeper First
- First, we upgraded Zookeeper to maintain compatibility
- Subsequently, ensured backward compatibility with existing Kafka version
- Finally, achieved zero service disruption
2: Rolling Kafka Upgrade
- Next, we deployed Kafka 3.1 with backward-compatible protocol
- During this phase, we maintained a mixed version cluster during transition
- Additionally, we updated Cruise Control simultaneously
3: Protocol Version Bump
- Lastly, we enabled latest inter-broker protocol
- Furthermore, we implemented gradual rollout with fallback compatibility
Phase 2: The Configuration Magic
Broker Setup (2 lines of config):
# Already had this for rack awareness
broker.rack={{ ec2_az_id }}
# This is the new magic
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
Consumer Setup (1 environment variable):
# Our SDK handles the rest automatically
export KAFKA_FETCH_FROM_CLOSEST_REPLICA=true
That’s it. Seriously.
Our internal SDK automatically:
- First, detects the host’s AZ from EC2 metadata
- Then, sets the
client.rackparameter - Finally, routes fetch requests to local replicas
Phase 3: Extending Beyond Basic Consumers
However, we didn’t stop at application consumers. Instead, we updated:
- Flink pipelines – Stream processing workloads
- Kafka Connect – Data integration pipelines
- Internal tooling – Monitoring and management tools
Ultimately, every consumer that could benefit got the upgrade.
The Results Will Shock You
Three months after rollout, the numbers spoke for themselves:
- 25% reduction in cross-AZ traffic
- 50% cut in network transfer costs
- Stable data consumption volume maintained
Furthermore, AWS Cost Explorer showed the impact immediately. Both ends of the traffic flow benefited:
- On one hand, brokers sent less cross-AZ data (steep cost drop)
- On the other hand, consumers received less cross-AZ data (another steep drop)
As a result, we achieved linear cost reduction with zero data loss or service degradation.
The Hidden Gotchas (And How to Handle Them)
Latency Trade-off: Up to 500ms Added
Reading from followers means waiting for replication lag. For ultra-low latency use cases, we kept the traditional leader-only approach.
Our decision framework:
- Cost-sensitive workloads → Closest replica
- Latency-critical workloads → Leader only
Maintenance Complexity Increased
Broker rotations became trickier. Consumers now connect to follower replicas, so “demoting” a broker doesn’t isolate it completely.
Our solution: Enhanced error handling and retry logic in consumer applications.
Load Balancing Challenges
Consumer distribution across AZs directly impacts broker load. Uneven consumer placement creates hot spots.
Our monitoring approach:
- Added AZ distribution metrics to our SDK
- Proactive consumer rebalancing
- Capacity planning per AZ
Beyond Kafka: The Bigger Picture
This wasn’t just about Kafka. We sparked a company-wide initiative to reduce Kafka traffic costs cross-AZ. Our service mesh team (Sentry) adopted similar strategies.
The ripple effect:
- Other teams audited their cross-AZ usage
- Shared learnings across engineering org
- Standardized cost optimization practices
Your Next Steps
Ready to implement this yourself? Here’s your action plan:
- Audit your current setup – Measure cross-AZ traffic baseline
- Plan the upgrade – Kafka 2.3+ required
- Test in staging – Verify latency impact for your workloads
- Gradual rollout – Start with non-critical consumers
- Monitor and optimize – Watch for load distribution issues
The Bottom Line
Sometimes the biggest wins come from the simplest changes. A few configuration tweaks saved us thousands monthly and will save hundreds of thousands annually.
Your Kafka bill doesn’t have to be a budget buster. With replica fetching, you can have both high availability and cost efficiency.
What’s your biggest cloud cost pain point? Reply and let me know – I’d love to hear what infrastructure challenges you’re tackling.
Tags: #Kafka #AWS #CostOptimization #Infrastructure #Engineering #DataStreaming #CloudCosts
Related: https://touchcyber.tech/securing-kubernetes-cluster-configuration/